告別繁瑣日志撈取 這款可視化開(kāi)源監(jiān)控系統(tǒng),重塑運(yùn)維效率
在當(dāng)今數(shù)字化浪潮中,信息系統(tǒng)運(yùn)行維護(hù)服務(wù)面臨著前所未有的挑戰(zhàn)。服務(wù)器日志,作為系統(tǒng)運(yùn)行的“黑匣子”,蘊(yùn)含著性能瓶頸、安全威脅與故障根源的關(guān)鍵信息。傳統(tǒng)的日志撈取方式——通過(guò)命令行逐臺(tái)登錄服務(wù)器、在浩如煙海的文本文件中篩選關(guān)鍵詞——不僅耗時(shí)費(fèi)力,更在問(wèn)題定位上存在嚴(yán)重滯后,往往讓運(yùn)維團(tuán)隊(duì)疲于奔命,陷入“救火隊(duì)員”的被動(dòng)角色。
正是在這樣的背景下,一款優(yōu)秀的可視化開(kāi)源監(jiān)控系統(tǒng)應(yīng)運(yùn)而生,它正徹底改變著運(yùn)維工作的范式,讓運(yùn)維人員得以從繁瑣重復(fù)的勞動(dòng)中解放出來(lái),將精力聚焦于更具價(jià)值的分析與優(yōu)化工作。
核心痛點(diǎn):傳統(tǒng)日志管理的桎梏
傳統(tǒng)運(yùn)維模式下,日志管理存在幾大痛點(diǎn):
- 分散與割裂:日志分散在各臺(tái)服務(wù)器、不同應(yīng)用與容器中,缺乏統(tǒng)一視角。
- 非實(shí)時(shí)性:?jiǎn)栴}發(fā)生后,才被動(dòng)地去追溯日志,錯(cuò)過(guò)了最佳干預(yù)時(shí)機(jī)。
- 可讀性差:原始日志晦澀難懂,需要專(zhuān)業(yè)知識(shí)和大量時(shí)間進(jìn)行解析。
- 效率低下:手動(dòng)操作極易出錯(cuò),且無(wú)法進(jìn)行大規(guī)模、跨時(shí)間維度的關(guān)聯(lián)分析。
破局利器:可視化開(kāi)源監(jiān)控系統(tǒng)的核心價(jià)值
現(xiàn)代的可視化開(kāi)源監(jiān)控系統(tǒng)(如Prometheus + Grafana的組合、Elastic Stack等明星方案)通過(guò)以下方式,為運(yùn)維服務(wù)帶來(lái)了革命性提升:
1. 統(tǒng)一采集與集中管理
系統(tǒng)通過(guò)輕量級(jí)的代理(Agent)或標(biāo)準(zhǔn)接口,自動(dòng)從各個(gè)服務(wù)器、容器、中間件和應(yīng)用中采集指標(biāo)數(shù)據(jù)與日志流。所有數(shù)據(jù)匯聚到中心存儲(chǔ),形成一個(gè)統(tǒng)一的“運(yùn)維數(shù)據(jù)湖”,打破了數(shù)據(jù)孤島。
2. 實(shí)時(shí)監(jiān)控與智能預(yù)警
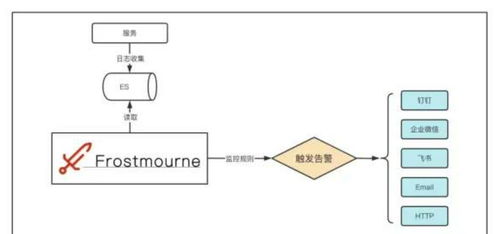
系統(tǒng)對(duì)采集到的性能指標(biāo)(如CPU、內(nèi)存、磁盤(pán)IO、網(wǎng)絡(luò)流量)和日志事件進(jìn)行實(shí)時(shí)處理與計(jì)算。通過(guò)預(yù)設(shè)的閾值或基于機(jī)器學(xué)習(xí)的異常檢測(cè)模型,系統(tǒng)能在問(wèn)題萌芽階段(如響應(yīng)時(shí)間變慢、錯(cuò)誤率上升)自動(dòng)觸發(fā)預(yù)警,通過(guò)郵件、釘釘、微信等渠道通知相關(guān)人員,變被動(dòng)為主動(dòng)。
3. 強(qiáng)大直觀的可視化展現(xiàn)
這是其得名的關(guān)鍵。系統(tǒng)提供豐富的儀表盤(pán)(Dashboard)功能,運(yùn)維人員可以通過(guò)拖拽方式,將核心指標(biāo)以折線(xiàn)圖、熱力圖、拓?fù)鋱D、地理分布圖等多種形式直觀展現(xiàn)。整個(gè)系統(tǒng)的健康狀態(tài)、性能趨勢(shì)、業(yè)務(wù)流量一目了然。更重要的是,可以直接在圖表上對(duì)異常點(diǎn)進(jìn)行下鉆(Drill-down),快速關(guān)聯(lián)查看到對(duì)應(yīng)的原始日志明細(xì),實(shí)現(xiàn)了從宏觀態(tài)勢(shì)到微觀根因的無(wú)縫追溯。
4. 強(qiáng)大的搜索與分析能力
集成高效的搜索引擎,支持對(duì)海量日志進(jìn)行全文檢索、模糊查詢(xún)和字段過(guò)濾。結(jié)合強(qiáng)大的查詢(xún)語(yǔ)言,可以輕松完成諸如“統(tǒng)計(jì)過(guò)去一小時(shí)來(lái)自特定IP的404錯(cuò)誤數(shù)量”、“找出所有包含‘Timeout’異常且響應(yīng)時(shí)間大于2秒的請(qǐng)求”等復(fù)雜查詢(xún),效率相比手工grep命令呈指數(shù)級(jí)提升。
5. 開(kāi)源生態(tài)與成本優(yōu)勢(shì)
作為開(kāi)源軟件,它們避免了商業(yè)軟件高昂的許可費(fèi)用。活躍的開(kāi)源社區(qū)提供了豐富的插件、集成方案和最佳實(shí)踐,能夠靈活適配各種技術(shù)棧(Kubernetes, Docker, MySQL, Nginx等)和業(yè)務(wù)場(chǎng)景。企業(yè)可以根據(jù)自身需求進(jìn)行定制化開(kāi)發(fā),掌控核心技術(shù)。
實(shí)踐場(chǎng)景:運(yùn)維效率的飛躍
- 故障排查:當(dāng)收到業(yè)務(wù)接口超時(shí)告警,運(yùn)維人員無(wú)需登錄服務(wù)器。只需在監(jiān)控儀表盤(pán)上點(diǎn)擊異常時(shí)間點(diǎn)的圖表,直接鏈接到相關(guān)應(yīng)用的錯(cuò)誤日志,快速定位是數(shù)據(jù)庫(kù)連接池耗盡,還是某個(gè)下游服務(wù)異常,將平均故障恢復(fù)時(shí)間(MTTR)大幅縮短。
- 容量規(guī)劃:通過(guò)長(zhǎng)期趨勢(shì)圖,清晰預(yù)測(cè)業(yè)務(wù)增長(zhǎng)帶來(lái)的資源壓力,為服務(wù)器擴(kuò)容或優(yōu)化提供數(shù)據(jù)支撐。
- 安全審計(jì):實(shí)時(shí)監(jiān)控異常登錄行為、敏感操作日志,并進(jìn)行可視化呈現(xiàn),助力安全合規(guī)。
- 性能優(yōu)化:分析各服務(wù)調(diào)用鏈路的耗時(shí)分布,直觀找出性能瓶頸所在。
****
引入一款功能強(qiáng)大的可視化開(kāi)源監(jiān)控系統(tǒng),對(duì)于信息系統(tǒng)運(yùn)行維護(hù)服務(wù)而言,已非錦上添花,而是提升效能、保障穩(wěn)定、驅(qū)動(dòng)創(chuàng)新的必然選擇。它讓運(yùn)維團(tuán)隊(duì)告別了在命令行海洋中“撈針”的窘境,轉(zhuǎn)變?yōu)樽凇榜{駛艙”內(nèi),通過(guò)全景式儀表盤(pán)掌控全局的指揮官。這不僅提升了系統(tǒng)的可靠性與安全性,更將運(yùn)維工作從成本中心推向價(jià)值創(chuàng)造的前沿,為業(yè)務(wù)的持續(xù)穩(wěn)定發(fā)展奠定了堅(jiān)實(shí)的基石。擁抱這樣的工具,就是擁抱高效、智能的運(yùn)維未來(lái)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.guangdong56.cn/product/60.html
更新時(shí)間:2026-06-11 15:16:16









